|
|
|
|
|
Next: 22.4 Handling Periodic Boundary Conditions |
|
|
|
|
|
|
Next: 22.4 Handling Periodic Boundary Conditions |
|
All the different steps in the separation of variable procedure as described may seem totally arbitrary. This section tries to explain why the steps are not arbitrary, but really quite logical. To understand this section does require that you have a good understanding of vectors and linear algebra. Otherwise you may as well skip this.
Partial differential equations are relatively difficult to understand.
Therefore we will instead consider an ordinary differential equation,
but for a vector unknown:
The initial conditions are:
If you want to solve this problem, the trick is to write ![]() in
terms of the so-called eigenvectors of matrix
in
terms of the so-called eigenvectors of matrix ![]() :
:
Now if you substitute the expression for ![]() into the
ordinary differential equation
into the
ordinary differential equation
The above equation can only be true if the coefficients of each
individual eigenvector is the same in the left hand side as in the right
hand side:
That are ordinary differential equations. You can solve these
particular ones relatively easily. The solution is
The entire process becomes much easier if the matrix ![]() is what is
called symmetric. For one, you do not have to worry about the matrix
being defective. Symmetric matrices are never defective. Also, you
do not have to worry about the eigenvalues possibly being complex
numbers. The eigenvalues of a symmetric matrix are always real
numbers.
is what is
called symmetric. For one, you do not have to worry about the matrix
being defective. Symmetric matrices are never defective. Also, you
do not have to worry about the eigenvalues possibly being complex
numbers. The eigenvalues of a symmetric matrix are always real
numbers.
And finally, the eigenvectors of a symmetric matrix can always be
chosen to be unit vectors that are mutually orthogonal. In other
words, they are like the unit vectors ![]() ,
, ![]() ,
, ![]() ,
..., of a rotated Cartesian coordinate system.
,
..., of a rotated Cartesian coordinate system.
The orthogonality helps greatly when you are trying to write ![]() and
and ![]() in terms of the eigenvectors. For example,
you need to write
in terms of the eigenvectors. For example,
you need to write ![]() in the form
in the form
Usually, however, you do not normalize the eigenvectors to length one.
In that case, you can still write
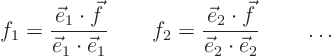
The next subsections will now show how all of the above carries over directly to the method of separation of variables for simple partial differential equations.
The previous subsection showed how to solve an example ordinary differential for a vector unknown. The procedure had clear similarities to the separation of variables procedure that was used to solve the example partial differential equation in section 22.1.
However, in the ordinary differential equation, the unknown was a
vector ![]() at any given time
at any given time ![]() . In the partial differential
equation, the unknown
. In the partial differential
equation, the unknown ![]() was a function of
was a function of ![]() at any given
time. Also, the initial conditions for the ordinary differential
equation were given vectors
at any given
time. Also, the initial conditions for the ordinary differential
equation were given vectors ![]() and
and ![]() . For the partial
differential equation, the initial conditions were given functions
. For the partial
differential equation, the initial conditions were given functions
![]() and
and ![]() . The ordinary differential equation problem had
eigenvectors
. The ordinary differential equation problem had
eigenvectors ![]() . The partial differential
equation problem had eigenfunctions
. The partial differential
equation problem had eigenfunctions ![]() .
.
The purpose of this subsection is to illustrate that it does not make that much of a difference. The differences between vectors and functions are not really as great as they may seem.
Let's start with a vector in two dimensions, like say the vector
![]()
![]()
![]() . You can represent this vector graphically as a point
in a plane, but you can also represent it as the 'spike function', as
in the left-hand sketch below:
. You can represent this vector graphically as a point
in a plane, but you can also represent it as the 'spike function', as
in the left-hand sketch below:
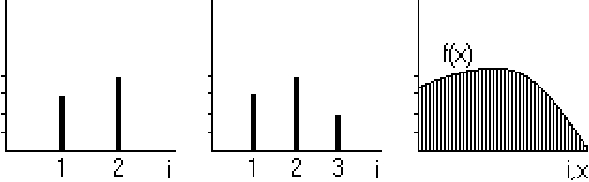
Phrased differently, you can think of a function ![]() as an infinite
column vector of numbers, with the numbers being the successive values
of
as an infinite
column vector of numbers, with the numbers being the successive values
of ![]() . In this way, vectors become functions. And vector
analysis turns into functional analysis.
. In this way, vectors become functions. And vector
analysis turns into functional analysis.
You are not going to do much with vectors without the dot product. The dot product makes it possible to find the length of a vector, by multiplying the vector by itself and taking the square root. The dot product is also used to check if two vectors are orthogonal: if their dot product is zero, they are orthogonal. In this subsection, the dot product is generalized to functions.
The usual dot product of two arbitrary vectors ![]() and
and ![]() can be found by multiplying components with the same index
can be found by multiplying components with the same index ![]() together and summing that:
together and summing that:
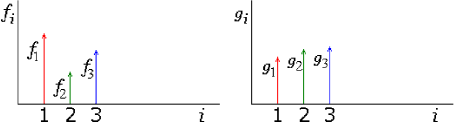
The three term sum above can be written more compactly as:
summation symbol.
The dot (or inner
) product of functions is defined in
exactly the same way as for vectors, by multiplying values at the same
![]() position together and summing. But since there are infinitely
many
position together and summing. But since there are infinitely
many ![]() -values, the sum becomes an integral:
-values, the sum becomes an integral:
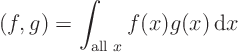 |
(22.1) |
As an example, the ordinary differential equation model problem
involved a given initial condition ![]() for
for ![]() . To solve
the problem, vector
. To solve
the problem, vector ![]() had to be written in the form
had to be written in the form
Similarly, the partial differential equation problem of section
22.1 involved a given initial condition ![]() for
for
![]() . To solve the problem, this initial condition had to be
written in the form:
. To solve the problem, this initial condition had to be
written in the form:
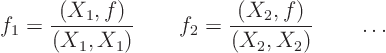
This section compares the solution procedure for the ordinary
differential equation

linear operator
But the difference between matrices and operators is not as great as
it seems. One way of defining a matrix ![]() is as a thing that, given a
vector
is as a thing that, given a
vector ![]() , can produce a different vector
, can produce a different vector ![]() ;
;
Since it was already seen that vectors and functions are closely related, then so are matrices and operators.
Like matrices have eigenvectors, linear operators have eigenfunctions.
In particular, section 22.1 found the appropriate
eigenfunctions of the operator above to be
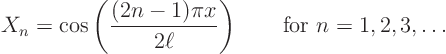
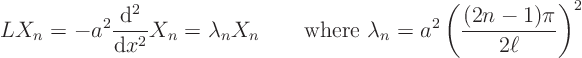
But, as the previous subsection pointed out, it was also assumed that these eigenfunctions are orthogonal. And that is not automatic. For a matrix the eigenvectors can be taken to be orthogonal if the matrix is symmetric. Similarly, for an operator the eigenfunctions can be taken to be orthogonal if the operator is symmetric.
But how do you check that for an operator? For a matrix, you simply
write down the matrix as a table of numbers and check that the
rows of the table are the same as the columns. You cannot do that
with an operator. But there is another way. A matrix is also
symmetric if for any two vectors ![]() and
and ![]() ,
,
Symmetry for operators can be checked similarly by whether they can be
taken to the other side in inner products involving any two functions
![]() and
and ![]() :
:
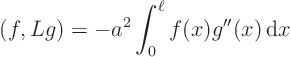
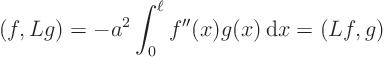
Some limitations to the similarity between vectors and functions should be noted.
One difference is that the functions in partial differential equations
must normally satisfy boundary conditions. The ones in the example
problem were
As long as matrix ![]() respects these boundary conditions, there is no
problem with that. In terms of linear algebra, you would be working
in a subspace of the complete vector space; the subspace of vectors
that satisfy the boundary conditions.
respects these boundary conditions, there is no
problem with that. In terms of linear algebra, you would be working
in a subspace of the complete vector space; the subspace of vectors
that satisfy the boundary conditions.
There is another problem with the analogy between vectors and
functions. Consider the initial condition ![]() for the solution
for the solution
![]() of the ordinary differential equation. You can give the
components of
of the ordinary differential equation. You can give the
components of ![]() completely arbitrary values and you will
still get a solution for
completely arbitrary values and you will
still get a solution for ![]() .
.
But now consider the initial condition ![]() for the solution
for the solution
![]() of the ordinary differential equation. If you simply give a
random value to the function
of the ordinary differential equation. If you simply give a
random value to the function ![]() at every individual value of
at every individual value of ![]() ,
then the function will not be differentiable. The partial
differential equation for such a function will then make no sense at
all. For functions to be meaningful in the solution of a partial
differential equation, they must have enough smoothness that
derivatives make some sense.
,
then the function will not be differentiable. The partial
differential equation for such a function will then make no sense at
all. For functions to be meaningful in the solution of a partial
differential equation, they must have enough smoothness that
derivatives make some sense.
Note that this does not mean that the initial condition cannot have some singularities, like kinks or jumps, say. Normally, you are OK if the initial conditions can be approximated in a meaningful sense by a sum of the eigenfunctions of the problem. Because the functions that can be approximated in this way exclude the extremely singular ones, a partial differential equation will always work in a subspace of all possible functions. A subspace of reasonably smooth functions. Often when you see partial differential equations in literature, they also list the subspace in which it applies. That is beyond the scope of this book.